Abstract
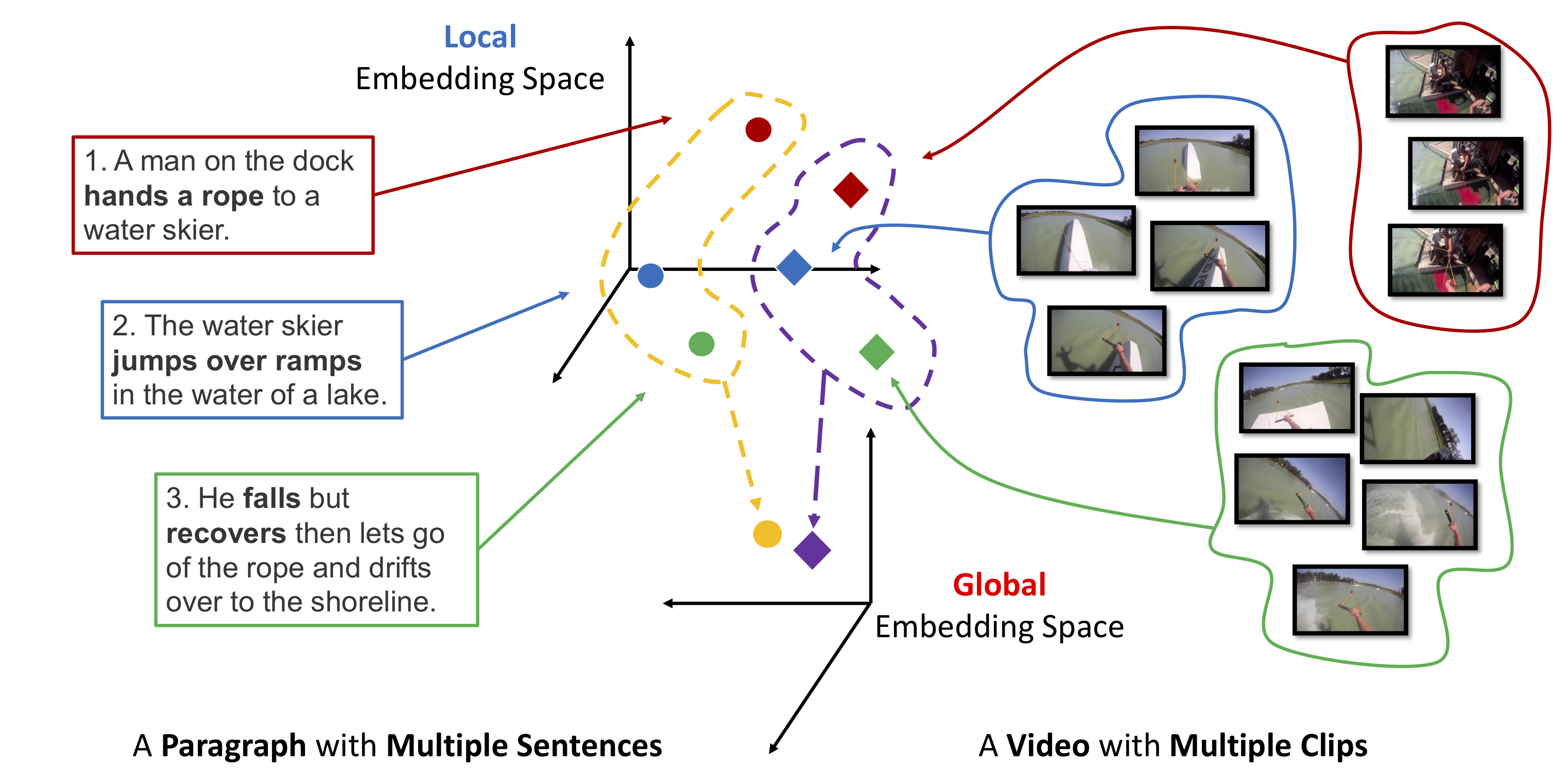
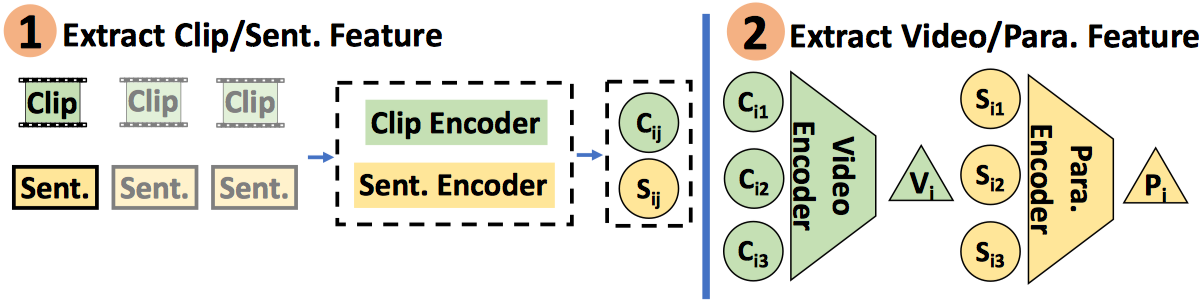
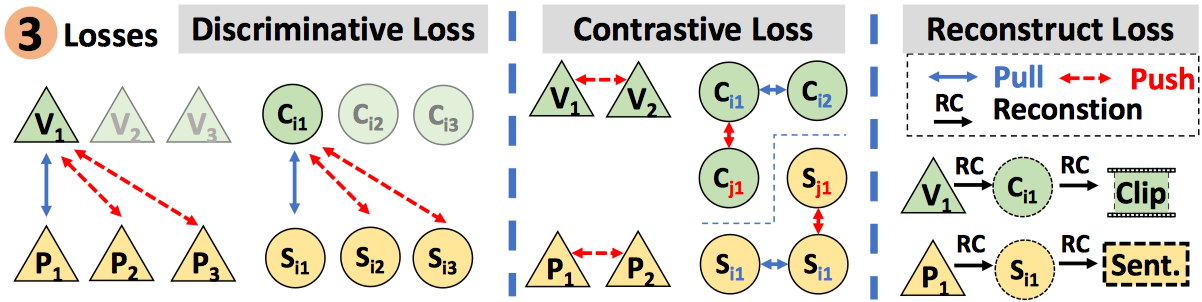
Visual data and text data are composed of information at multiple granularities. A video can describe a complex scene that is composed of multiple clips or shots, where each depicts a semantically coherent event or action. Similarly, a paragraph may contain sentences with different topics, which collectively conveys a coherent message or story. In this paper, we investigate the modeling techniques for such hierarchical sequential data where there are correspondences across multiple modalities. Specifically, we introduce hierarchical sequence embedding (hse), a generic model for embedding sequential data of different modalities into hierarchically semantic spaces, with either explicit or implicit correspondence information. We perform empirical studies on large-scale video and paragraph retrieval datasets and demonstrated superior performance by the proposed methods. Furthermore, we examine the effectiveness of our learned embeddings when applied to downstream tasks. We show its utility in zero-shot action recognition and video captioning.